语言 AI 原来知道自己的回答是否正确!伯克利等高校新研究火了,网友:危险危险危险
语言 AI,具备了人类的自我审视能力:最近,一个来自加州大学伯克利分校和霍普金斯大学的学术团队研究表明:它不仅能判断自己的答案正确与否,而且经过训练,还能预测自己知道一个问题答案的概率。

研究成果一经发布,就引起热议,有人的第一反应是恐慌:

也有人认为,这项成果,对神经网络研究具有正面意义:

语言 AI 具备自我审视能力
研究团队认为,如果要让语言 AI 模型自我评估,必须有一个前提:语言 AI 回答问题时,会校准自己的答案。
这里的校准,就是语言 AI 预测一个答案的正确概率,是否与实际发生的概率一致。只有这样语言 AI 才可以运用这种校准的能力来评估自己输出的答案是否正确。
所以第一个问题是,语言 AI 能否对自己的答案进行校准?为了证明这个问题,研究团队为 AI 准备了 5 个选择题:
答案选项,以 A、B、C 的形式给出。如果 AI 模型答案的正确率超过偶然几率,那么就证明 AI 模型给出的答案是经过校准的。
而测试的结果是,语言 AI 给出的答案,正确率明显超过任意选项的偶然几率。也就是说,语言 AI 模型可以对自己的答案进行很好的校准。
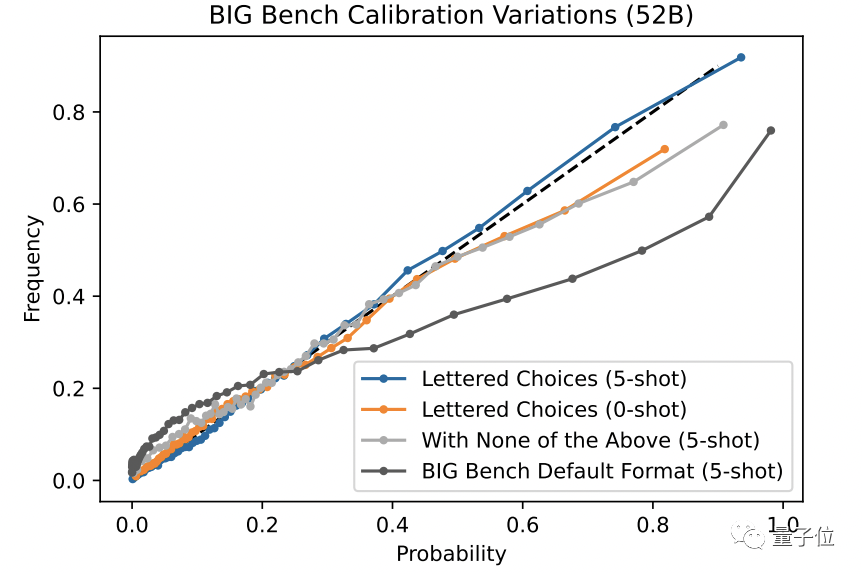
但研究团队发现,语言 AI 的校准能力,是建立在选项答案明确的前提下的。如果在选项中加入一个“以上都不是”的不确定选项,就会损害语言 AI 的校准能力。
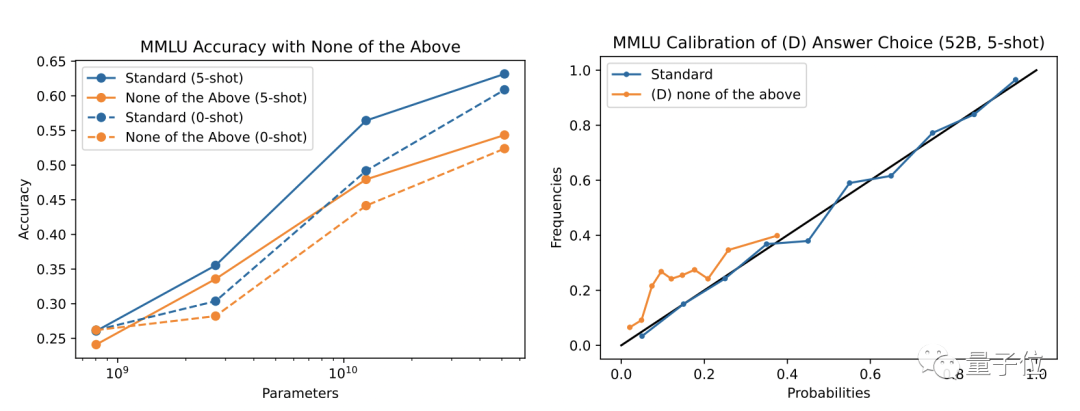
也就是说,在特定格式的选择题中,语言 AI 模型可以对答案进行很好的校准。明确了这个前提之后,下一个问题是,验证语言 AI 模型能够判断自己的答案是否正确。
在这一轮的测试中,为了能让 AI 模型的预测更接近自己的有效决策边界。研究团队仍然选择上一轮测试的问题,以及语言 AI 模型的答案样本。
同时让 AI 模型选择自己的答案真假与否,之后再针对这个“真”或“假”的答案,分析 AI 模型是否做出有效的校准。问题设置举例如下:

在经过 20 次的真假测试之后,研究团队发现,语言 AI 模型对自己答案或“真”或“假”的评价,都经过明显的校准。
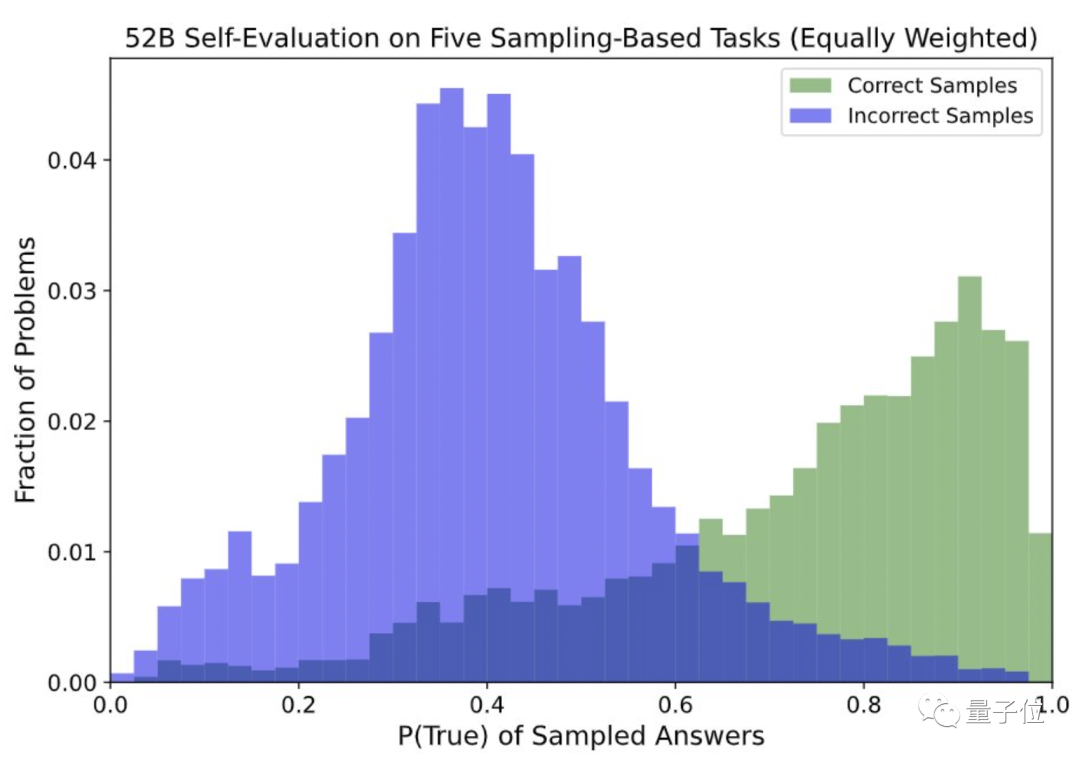
也就是说,如果在一个范围内,给 AI 模型提出若干问题,然后 AI 模型对这些问题的答案进行真假评价,具有合理的,且经过校准的置信度。
这也证明,语言 AI 模型确实可以判断自己对一个问题的主张是否正确。
最后,研究团队对语言 AI 模型提出了一个更难的问题:AI 模型经过训练,能否预测他们是否知道任何给定问题的答案。
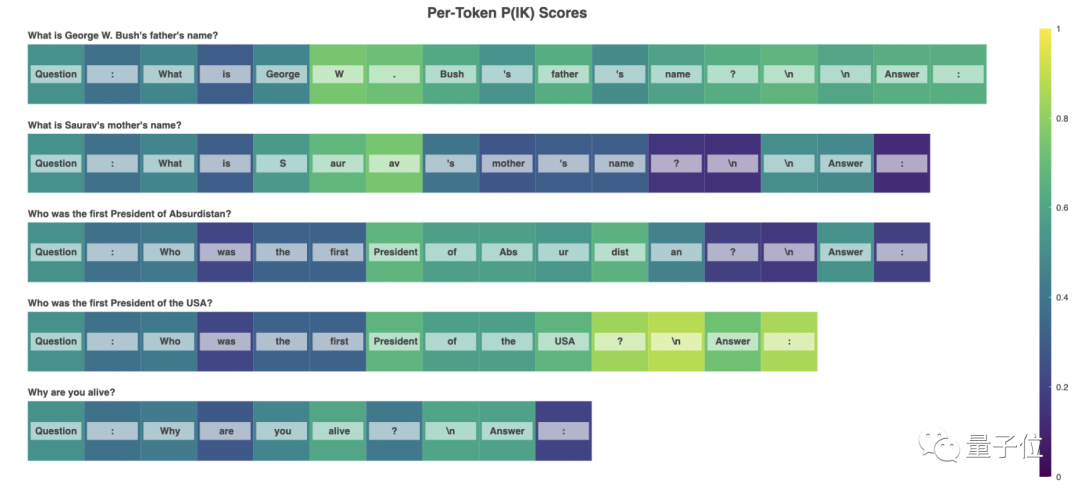
在这一环节,研究团引入一个数据 P (IK)(我知道这个答案的概率)并在下面两种训练方式中挑选一种进行训练:
Value Head(价值导向): 把 P (IK) 训练成为一个额外的价值导向,再添加到模型的对数(独立于语言建模的对数,这种方法的优势在于,研究团队可以很容易的探测 P (IK) 的一般标记位置。
Natural Language(自然语言):这种方法比较简单,就是要求 AI 模型从字面上回答“你知道这个答案的概率是多少”,同时输出一个百分比数据答案。

在训练初期,研究团队比较倾向于自然语言训练方式,但结果并不显著,由此转向价值导向方式,不过研究团队同时表示,最终对 AI 模型的训练还将回归自然语言方法。
在经过训练之后,研究团队发现,语言 AI 模型可以很好的预测 P (IK),并且在不同类型的问题中,这种预测能力具有部分通用性。
不过,研究团队也发现,在某些类型的问题,比如算术问题,语言 AI 模型在 OOD 校准时有一些困难。
对于这一学术成果,研究团队表示,将来的方向,是将这些成果,推广到语言 AI 模型不模仿人类文本的前提下,自我学习和事实推理领域。
作者介绍

论文通讯作者 Jared Kaplan 博士,是一位理论物理学家,同时也是一位机器学习专家,现担任霍普金斯大学助理教授,主要研究领域,机器学习研究,包括神经模型的缩放规律以及 GPT-3 语言模型。
共同通讯作者 Saurav Kadavath,Anthropic 公司研究员,现在加州大学伯克利分校 EECS 专业攻读硕士学位,主要研究领域是机器学习,大规模语言学习等。
参考链接:
https://arxiv.org/abs/2207.05221
相关文章
- 微软 PowerToys 新增“高级粘贴”功能:实时转换剪贴板内容
- 超半数用户未在 Win11 上使用过 Copilot,微软:暂缓 Copilot 新功能推出
- 人工智能主要应用哪几个方面(人工智能应用有哪些方面)
- OpenAI推出漏洞奖励计划:寻找人工智能系统漏洞有奖
- 诺奖得主:AI从缩短工作时间到提升工作幸福感
- 网络安全公司开发AI工具,1分钟破解大部分常见密码
- 康奈尔大学研究团队开发无声沟通技术,利用声纳眼镜执行任务
- 人工智能芯片性能与功率效率,高通战胜英伟达成最大赢家
- 网络安全公司警告:超过一半常规密码可在1分钟内被破解
- 映宇宙集团接入GPT3.5 turbo和审核中的GPT4,将进一步提升语言处理能力
- 昇思MindSpore:人工智能的创新之源
- 史玉柱:未来游戏公司应重点布局游戏+AI领域
- 人工智能技术制作“特朗普被捕”照片引发担忧
- 海天瑞声:大模型和AIGC领域带来更多机遇和挑战
- 必应聊天中已有广告出现 用户质疑AI中立性
- AI研究人员呼吁暂停研发更先进的AI技术
系统下载排行榜71011xp
番茄花园Win7 64位推荐旗舰版 V2021.05
2深度技术Win7 64位豪华旗舰版 V2021.07
3番茄花园Win7 64位旗舰激活版 V2021.07
4带USB3.0驱动Win7镜像 V2021
5系统之家 Ghost Win7 64位 旗舰激活版 V2021.11
6萝卜家园Win7 64位旗舰纯净版 V2021.08
7技术员联盟Win7 64位旗舰激活版 V2021.09
8雨林木风Win7 SP1 64位旗舰版 V2021.05
9萝卜家园Ghost Win7 64位极速装机版 V2021.04
10技术员联盟Win7 64位完美装机版 V2021.04
深度技术Win10 64位优化专业版 V2021.06
2深度技术Win10系统 最新精简版 V2021.09
3Win10超级精简版 V2021
4Win10完整版原版镜像 V2021
5风林火山Win10 21H1 64位专业版 V2021.06
6Win10光盘镜像文件 V2021
7深度技术 Ghost Win10 64位 专业稳定版 V2021.11
8技术员联盟Ghost Win10 64位正式版 V2021.10
9Win10 21H1 Build 19043.1320 官方正式版
10技术员联盟Win10 64位永久激活版镜像 V2021.07
系统之家 Ghost Win11 64位 官方正式版 V2021.11
2Win11PE网络纯净版 V2021
3系统之家Ghost Win11 64位专业版 V2021.10
4Win11官网纯净版 V2021.10
5Win11 RTM版镜像 V2021
6番茄花园Win11系统64位 V2021.09 极速专业版
7Win11专业版原版镜像ISO V2021
8Win11官方中文正式版 V2021
9Win11 22494.1000预览版 V2021.11
10番茄花园Win11 64位极速优化版 V2021.08
深度技术Windows XP SP3 稳定专业版 V2021.08
2雨林木风Ghost XP Sp3纯净版 V2021.08
3萝卜家园WindowsXP Sp3专业版 V2021.06
4雨林木风WindowsXP Sp3专业版 V2021.06
5风林火山Ghost XP Sp3纯净版 V2021.08
6技术员联盟Windows XP SP3极速专业版 V2021.07
7萝卜家园 Windows Sp3 XP 经典版 V2021.04
8番茄花园WindowsXP Sp3专业版 V2021.05
9电脑公司WindowsXP Sp3专业版 V2021.05
10番茄花园 GHOST XP SP3 纯净专业版 V2021.03
热门教程 更多+
装机必备 更多+
重装教程 更多+
电脑教程专题 更多+



